


Master Prompt Engineering: LLM Embedding and Fine-tuning

Fine-tuning and embedding LLMs (GPT-3/3.5/4) have become a popular topic of discussion as people seek to leverage the power of this advanced language model for various applications, such as question-answering (QA) and information retrieval.
While both semantic embeddings and fine-tuning are techniques employed to adapt LLMs to specific tasks, they serve different purposes and offer unique benefits.
We will explore these two concepts together as they are related and there is often much confusion about which to use and when.
Core Concepts
Semantic Embeddings: Representation and Applications
Semantic embeddings are numerical vector representations of text that capture the semantic meaning of words or phrases. By comparing and analyzing these vectors, similarities and differences between textual elements can be discerned.
Leveraging semantic embeddings for search enables the quick and efficient retrieval of relevant information, particularly within large datasets. Semantic search boasts several advantages over fine-tuning, such as faster search speeds, reduced computational costs, and the prevention of confabulation or fact fabrication. Owing to these benefits, semantic search is often favoured when the objective is to access specific knowledge within a model.
Embeddings find applications in various domains, including recommendation engines, search functionality, and text classification. For example, when designing a movie recommendation engine for a streaming platform, embeddings can identify movies with similar themes or genres based on their textual descriptions. By representing these descriptions as vectors, the engine can calculate distances between them and recommend movies in close proximity within the vector space, ensuring a more accurate and relevant user experience.
Fine-Tuning: Enhancing Model Responses
Fine-tuning is a technique employed to refine the performance of pre-trained models, such as chatbots. By providing examples and adjusting the model's parameters, fine-tuning enables the model to generate more accurate and contextually relevant responses for specific tasks. These tasks can range from chatbot conversations and code generation to question formation, ensuring better alignment with the desired output. The process is akin to a neural network adjusting its weights during training.
For instance, in customer service chatbots, fine-tuning can enhance the chatbot's understanding of industry-specific terms or jargon, leading to more accurate and pertinent responses to customer inquiries.
As a form of transfer learning, fine-tuning adapts a pre-trained model to perform new tasks without necessitating extensive retraining. The process involves making minor adjustments to the model's parameters, allowing it to better execute the target task.
However, fine-tuning large language models (GPT-3/3.5/4) presents its own set of challenges. A common misconception is that fine-tuning will enable the model to acquire new information, but in reality, it teaches the model new tasks or patterns, not new knowledge. Furthermore, fine-tuning can be time-consuming, complex, and costly, limiting its scalability and practicality for numerous use cases.
The value of teaching specific tasks: One of the primary benefits of fine-tuning is its ability to teach the model specific tasks or patterns, enabling it to perform more effectively in those areas. For instance, fine-tuning can be used to improve the model's capability in tasks like email generation, code creation, or even long-form fiction writing. By focusing on these specific tasks, the model can provide more accurate, relevant, and contextually appropriate outputs tailored to the user's needs.
It is important to note that fine-tuning LLMs does not involve teaching new knowledge. The model's pre-training phase already provides it with a wealth of information, and fine-tuning merely adjusts the model to generate text that aligns with a desired pattern. In essence, fine-tuning helps LLMs understand and produce the appropriate structure for a particular task, without introducing new knowledge.
Challenges of Fine-tuning vs Embedding
Main Challenges of Fine-tuning a Large Language Model like GPT-3
Fine-tuning a large language model (LLM) such as GPT-3 presents several challenges that can affect its efficiency, scalability, and effectiveness. In this section, we will discuss the main challenges associated with fine-tuning LLMs:
Computational Costs: Fine-tuning LLMs requires considerable computational resources, which can be expensive and may not be feasible for organizations or researchers with limited budgets. These costs can limit the applicability of fine-tuning in various use cases.
Training Data Quality: High-quality and relevant training data is essential for successful fine-tuning. However, sourcing and preparing this data can be time-consuming and challenging, and there is always a risk of introducing biases or inaccuracies that could affect the model's performance.
Overfitting: Overfitting occurs when the model becomes too specialized in the training data, resulting in poor generalization to new examples. This can be a significant challenge in fine-tuning LLMs, as the balance between specialization and generalization is critical to achieving optimal performance.
Confabulation and Hallucination: Fine-tuning LLMs can sometimes lead to confabulation, where the model produces incorrect or fabricated information, and hallucination, where it generates plausible but incorrect answers. This may undermine the reliability and trustworthiness of the model's output.
Model Adaptability: When new information or updated knowledge becomes available, re-fine-tuning the model may be necessary. This process can be resource-intensive and cumbersome, especially if the model needs to be updated frequently to stay current and relevant.
Ethical Considerations: Fine-tuning LLMs can result in potential biases, as they may inadvertently learn and propagate harmful stereotypes or misinformation from the training data. Ensuring the ethical use and output of the fine-tuned model can be challenging and requires continuous monitoring and evaluation.
Challenges with Embeddings in Large Language Models
Despite their importance, there are several challenges associated with embeddings in LLMs:
High-dimensionality: Embeddings generated by LLMs often have a high dimensionality, which can lead to increased computational complexity and storage requirements. This can make it challenging to work with large-scale datasets and perform efficient similarity search, clustering, or classification tasks.
Sparse representation: Embeddings may result in sparse representations, where most of the elements in the vector are zeros or near-zero values. This sparsity can lead to increased memory consumption and slower computation times during similarity searches or other tasks.
Interpretability: Embeddings are often difficult to interpret, as they represent complex relationships in a high-dimensional space. This lack of interpretability can make it challenging to diagnose issues, such as biases or inaccuracies in the embeddings, and to understand the underlying reasoning of the model.
Data quality: The effectiveness of embeddings heavily depends on the quality of the input data used for training the LLM. Noisy, biased, or poorly-formatted data can lead to suboptimal embeddings, resulting in reduced performance in downstream tasks.
Domain adaptation: While pre-trained LLMs can generate general-purpose embeddings, adapting these embeddings to specific domains or tasks may require additional fine-tuning or training on domain-specific data. This process can be resource-intensive and requires expertise in model training and optimization.
Out-of-vocabulary words: In some cases, the LLM might encounter words or phrases that were not present in the training data. This out-of-vocabulary (OOV) words can result in suboptimal or inaccurate embeddings, as the model has limited information to generate a meaningful representation.
Language coverage: Many LLMs are trained on data primarily from English or other widely-spoken languages, which may limit the quality of embeddings for low-resource languages. This can lead to reduced performance in tasks involving less-represented languages.
Bias and fairness: Embeddings can unintentionally capture and perpetuate biases present in the training data, such as gender, racial, or cultural biases. These biases can then influence the model's behaviour in downstream tasks, raising concerns about fairness and ethical implications.
Overview of the Fine-tuning Process
Define your objective: Clearly identify the task or domain you want the model to specialize in, such as sentiment analysis, summarization, or a specific subject area.
Collect and preprocess data: Gather a dataset relevant to your objective. This dataset should contain examples of the desired input-output pairs. Preprocess the data to ensure it is clean, consistent, and formatted correctly.
Split the data: Divide your dataset into training, validation, and testing sets. The training set is used to fine-tune the model, the validation set helps in monitoring the model's performance during training and selecting the best model, and the testing set is used to evaluate the final model's performance.
Choose the fine-tuning configuration: Select the appropriate model architecture, learning rate, batch size, and other hyperparameters for fine-tuning. This may require some experimentation and hyperparameter tuning to find the best configuration.
Fine-tune the model: Initialize LLM with the pre-trained weights and start the fine-tuning process. Train the model on your training dataset for a number of epochs or until the validation performance stops improving.
Monitor and evaluate performance: Regularly check the model's performance on the validation set during training. This helps identify overfitting or underfitting, and you can stop training when the performance on the validation set stops improving.
Select the best model: Choose the iteration of the model with the highest performance on the validation set.
Evaluate using the test set: Assess the fine-tuned model's performance on the test dataset to get an unbiased estimate of its generalization ability.
Deploy the model: Once the fine-tuning process is complete and the model's performance is satisfactory, deploy the model in your application or system.
Monitor and maintain: Continuously monitor the model's performance in real-world scenarios, and fine-tune or retrain it as needed to ensure optimal performance.
Overview of Embedding and Vector Search with LLM:
The embedding process is an essential component of large language models (LLMs) like GPT-3/Gpt-3.5/GPT-4, as it allows for semantic understanding and representation of text in a numerical format. Here is a step-by-step overview of the embedding process for LLMs:
Source relevant data: Collect textual data that is relevant to the domain or task you want the model to understand. This could include documents, articles, research papers, or web pages covering the topics of interest.
Pre-process data: Clean and sanitize the text data by removing irrelevant or sensitive information, correcting grammar and spelling errors, and formatting the text for further processing.
Tokenization: Tokenize the pre-processed text into individual words, subwords, or characters, depending on the requirements of the language model. This process breaks down the text into smaller units that can be processed by the LLM.
Embedding: Pass the tokenized text through the language model to generate embeddings, which are numerical representations of the text in a high-dimensional space. These embeddings capture the semantic meaning of the text and enable the model to perform various tasks, such as similarity search, clustering, or classification.
Dimensionality reduction (optional): If needed, reduce the dimensionality of the generated embeddings using techniques like PCA or t-SNE. This step can help improve the efficiency of similarity search and other downstream tasks.
Indexing and storage: Index the generated embeddings using an appropriate data structure, such as a vector database or an inverted index, to facilitate fast and efficient retrieval during search or query processing.
Search and retrieval: Use the indexed embeddings to perform similarity search or other tasks by comparing the embeddings of user queries with those of the indexed text. Retrieve the most relevant documents or text chunks based on the similarity scores or other relevance criteria.
Post-processing: Extract relevant information from the retrieved documents or text chunks, such as metadata or specific sections of interest, to provide a comprehensive and informative response to the user's query.
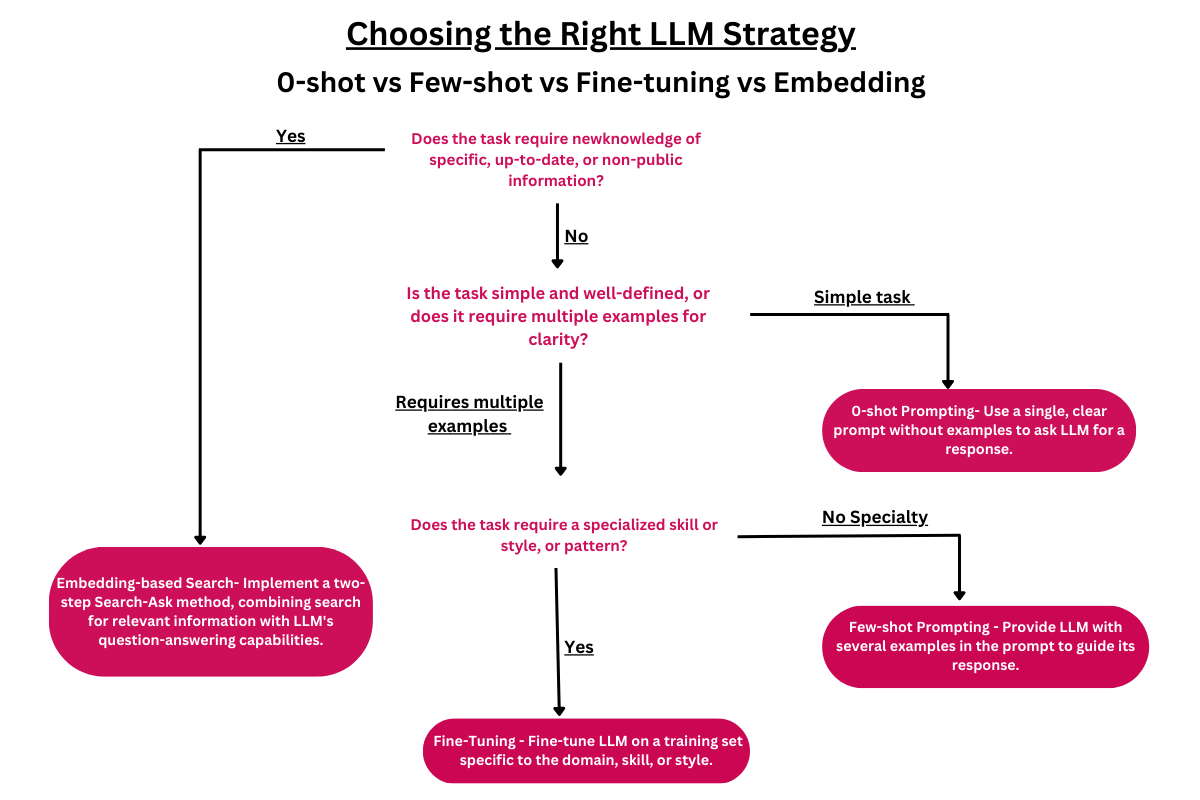
Choosing Between Embeddings and Fine-tuning
While there is some overlap in their applications, the choice between using embeddings or fine-tuning depends on the problem at hand. For search and recommendation tasks, embeddings are generally more suitable, as they allow for the efficient comparison of textual data. For instance, in chatbot response generation, fine-tuning is the preferred method, as it enhances the model's performance in generating appropriate responses to user inputs.
Semantic Embeddings vs Fine-Tuning
It is crucial to understand that semantic embeddings and fine-tuning are two separate methodologies for harnessing the power of language models like GPT-3. Fine-tuning concentrates on teaching the model new tasks via transfer learning, while semantic embeddings involve converting the text's meaning into a numerical representation, which can be employed in tasks such as semantic search and information retrieval.
Semantic search, also referred to as neural search or vector search enables databases to search and retrieve information based on semantic meaning rather than solely on keywords or indexes. This approach is highly scalable and typically faster and more cost-effective than fine-tuning a model for a specific task.
In contrast, fine-tuning can be time-consuming, complex, and costly, and does not inherently enhance the model's capacity to store and retrieve new information. Moreover, fine-tuning large language models for QA might not always be the most efficient or effective solution, as it continues to face issues such as confabulation (producing inaccurate or fabricated information) and hallucination (generating plausible but incorrect answers).
One might argue that every search problem can be formulated as a question-and-answer task. While this is true to some extent, the choice between using embeddings and fine-tuning for question-answering depends on the specific requirements and complexity of the problem. For simpler search tasks, embeddings can be more efficient and easier to implement, whereas, for more complex question-answering scenarios, fine-tuning may provide better results.
Summary
Fine-tuning GPT-3/3.5/4
Teaches new tasks or patterns
Originally created for image models, now applies to NLP tasks
Used for classification, sentiment analysis, and named entity recognition
Does not teach new information, only new tasks
Prone to confabulation and hallucination
Expensive, slow, and difficult to implement
Not scalable for large datasets
Embedding & Semantic Search
Also known as neural search or vector search
Adds to the LLMs knowledge base
Uses semantic embeddings to represent text meaning
Scales well, fast, and cost-effective
Searches based on context and topic, not just keywords
Easily updates with new information
Solves half of the QA problem by retrieving relevant information
Comparing Fine-tuning and Semantic Search
Fine-tuning
Slow, difficult, and expensive
Prone to confabulation
Teaches new tasks, not new information
Requires constant retraining
Not ideal for QA tasks
Semantic Search
Fast, easy, and cheap
Recalls exact information
Easy to add new information
Scalable and efficient
Solves half of QA tasks by retrieving relevant documents
Both fine-tuning LLMs and semantic embeddings offer unique advantages in the field of natural language processing, each catering to specific needs and tasks. While semantic search is optimal for quickly and accurately retrieving knowledge, fine-tuning focuses on generating structured and patterned text that aligns with a specific task or application.
Fine-tuning LLMs excels at teaching new tasks or patterns, but may not be ideal for QA tasks due to its inherent limitations and technical complexities. In contrast, semantic search is better suited for QA tasks, providing efficient retrieval of relevant information and scalability. By recognizing the distinct strengths of these two approaches, users can make informed decisions about which method best addresses their particular objectives.